KATE is using a version of the nearest neighbor algorithm for computing similarity metrics. A simplified version of this algorithm is described here. For a further description, see [6]. For a discussion on k -Nearest Neighbor algorithms, see [24].
The similarity between two cases x and y having p features is:
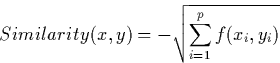
Where f is defined as:
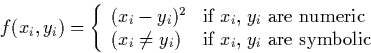
The algorithm is then:
Classified Data = 0
for each Case x in Casebase do
1. for each y in Classified Data do
Sim(y) = Similarity(y,x)
2. y_max = (y_1,...,y_k) such that Sim(y_k) = max(K-nearest neighbors)
3. if class(y_max) = class(x)
then classification is correct
Classified Data = Classified Data + {x}
else classification is incorrect