
Norges Teknisk-Naturvitenskaplige Universitet (NTNU)
Institutt for Datateknikk og Telematikk (IDT)
Cray T3E har en skalerbar og fleksible arkitektur. T3E er en MIMD (Multiple Instructions, Multiple Data) MPP (Massiv Parallell Prosessering) maskin basert på sin forgjenger, T3D (omtalt i pensumbok [HWAN93] side 423-24). Den kan leveres med fra 16 - 2048 prosessorer. T3E bruker Digitals Alfa-prosessor EV5 (DECchip 21164), som har en maksimal ytelse på 600 MFLOPS. Hver node kan utstyres med fra 64MB til 2GB RAM. Total Toppytelse på maskiner er 1.2 TFLOPS!
Det som er nytt med Cray T3E er at de påstår at systemet er veldig skalerbart. Skalerbart betyr ikke bare at det er mulig å sette inn flere prosessorer og installere mer RAM. I et skalerbart system må alle systemkomponentene kunne skaleres. Operativsystemet, interprosessor kommunikasjon, I/O arkitektur osv. må kunne utbygges. Det som er viktig er at man ikke får såkalte flaskehalser : F.eks. hvis det er mulig å legge til mange prosessorer, men I/O systemet er rimelig statisk. Da vil en fort få en flaskehals.
T3E er andre fase i Crays MPP utviklingsprogram. Det begynte med 1024 noders T3D med 150 GFLOPS topp-ytelse og senere en 2048 noders T3D med 300 GFLOPS. T3E er andre fase (1995-1997 i figur 8.12 i [HWAN93] stemmer rimelig bra !), og Cray har fortsatt et mål om å nå 1 TFLOP sustained ytelse før år 2000 (fase 3).
De mulige system-konfigurasjonene som finnes er gjengitt i Tabell 2-1.
| Bruker PE'er | Minne | Ytelse | I/O båndbredde | |
| Luftavkjølt | 16 til 128 | 1 til 256 GB | 9.6 til 76.8 GFLOPS | 2 til 16 GB/s |
| Veskeavkjølt | 64 til 2048 | 4 GB til 4 TB | 38.4 GFLOPS til 1.2 TFLOPS | 4 til 128 GB/s |
Tabell 2-1 : Mulige system konfigurasjoner
I tillegg til bruker-PE'er er det i gjennomsnitt en support-PE for hver 16. bruker-prosessor. Disse brukes til globale operativsystemfunksjoner og som redundante prosessorer hvis noen av bruker-prosessorene skulle falle ut.
Minne kan fåes i følgende størrelser : 64, 128, 256, 512, 1024 eller 2048 MB. Alle prosessorer i en modul må ha samme minnestørrelse.
Luftavkjølte versjoner kommer i fra 1 til 6 kabinetter. Systemet er delt inn i moduler av 4 PE'er og ett GigaRing Interface. Man kan kun legge til hele moduler. En luftavkjølt Cray T3E er vist i Figur 2-1.
Den veskeavkjølte versjonen leveres i 1 til 8 kabinetter og her består hver modul av 8 PE'er og et GigaRing interface. En veskeavkjølt Cray T3E er vist på forsiden av denne rapporten.
Prisen på et T3E system heller ikke så avskrekkende sammenlignet med andre MPP maskiner. Den billigste modellen, 16 PE'er - 1 GB RAM - 9.6 GFLOPS toppytelse - luftavkjølt, er på under 1 million US dollar. En maskin med 1024 PE'er, 64 GB RAM, 600 GFLOPS toppytelse er på 39.7 millioner US dollar. Dette er listepriser i USA.
 Figur 2-1:
Luftavkjølt T3E
Figur 2-1:
Luftavkjølt T3E
NTNU har gått til innkjøp av en Cray T3E. Navnet
på denne maskinen er huge.ntnu.no og skal etter planen
leveres høsten 1996. Huge har den konfigurasjonen som er
vist i Tabell 2.1.
Huge vil, sammen med Bure (en Cray J916/8128) bli hjørnesteinen i NTNU's tungregnings-satsing.
| Prosessorer | 64 DEC Alpha EV5 |
| Minne | 128 Mbyte pr. prosessor Totalt : 8.2 Gbyte. |
| Disk | 64 Gbyte |
| Toppytelse | 600 MB pr. prosessor Totalt : 38.4 GFLOPS. |
Tabell 2-1 : NTNUs nye supermaskin, Huge
 Figur 2-2 : DECchip 21164
Figur 2-2 : DECchip 21164
I en parallellmaksin er det ikke bare viktig å ha mange prosessorer, men også at hvert prosessor element (PE) er så raskt som mulig. Cray har valgt å bruke den raskeste prosessoren som finnes i dag, nemlig DECchip 21164 (kilde : BYTE, april 1996 s. 40, Benchmark Update). Denne DEC Alpha EV5 prosessoren er en 64 bits RISC prosessor som er cache basert, har instruksjonssamlebånd, kjører flere instruksjoner pr. sekund og støtter IEEE flyttallsopersasjoner (både 32 bits og 64 bits). Fordelen med en 64 bits prosessor er at man kan, selv med et delt lager, ha lager på inntil 18.000.000 TByte med data. Alpha EV5 kjører på 300 MHz og har fire instruksjonsveier. Den kan gjøre 2 flyttallsoperasjoner pr. sekund. Det fører til at den får en teoretisk toppytelse på 600 MFLOPS. Det er det høyeste èn prosessor kan levere i dag.
Et prosesseringselement består av Alpha-prosessoren, lokalt minne (fra 64 MB til 2GB) og kontroll-logikk som Cray selv har laget.

T3E har et delt, globalt minne subsystem som gjør at alle prosessorene kan nå alt minne som finnes i maskinen. Dette gjør det mulig å bruke delt lager programmeringsteknikker på denne maskinen, i tillegg til meldingsutveksling.
Den delte lager modellen på T3E er en UMA-modell (Uniform Memory Access), da alle prosessorer kan lese hele lageret. Men man kan allikevel ikke si at det er snakk om tett kobling, da de ikke fysisk deler mange resurser. Delt lager muliggjøres ved hjelp av et minne-delsystem, og hver prosessor har sitt eget lager.
Cray har klart å komme i nærheten av Moore's lov : Doblet ytelse hver 18-24 måned. Moore's lov er egentlig at antall transistorer på en IC-brikke dobler seg hver ca. 18 måned. Dette aksiomet ble foreslått av Gordon Moore, som først så denne trenden tidlig på 1960 tallet.
Hvert prosesseringselement (PE) i Cray T3E er knyttet sammen i en toveis 3D Torus. Denne torusen har en meget høy bånbredde og lav latency (ventetid til første byte kommer frem). I en toveis 3D torus er hvert element knyttet sammen med det før og etter i hver dimensjon (3 i dette tilfellet). Kommunikasjonsveiene i hver retning er også sykliske. Hastigheten på linjene i torusen er imponerende : Linjene greier 480 Mbytes/s i hver retning ! I en T3E med 512 elementer tilsvarer dette en "bisection bandwidth" på hele 122 GBytes/s.
I Cray T3E er det implementert adaptiv ruting. Med å bruke denne metoden for ruting blir pakker sendt rundt midlertidige "hot-spots".
Latency hiding (redusering av ventetid ved lager-aksess) og synkronisering gjøres med 512 minne mapped E-registere. Ventetiden ved en minneaksess til et minneelement utenom prosessoren gjøres ved å bruke E-registerene som en minne-vektor-port. Dette gjør det mulig for en strøm av minne-forespørsler å flyte på en samlebånds-lignende måte. Resultatene kommer flytende tilbake, og i mellomtiden kan PE'en jobbe med andre oppgaver. Dette er en variant av Relaxed Memory Consistency modellene beskrevet i [HWAN93]. Men man kombinerer denne med en Multiple-contexts modell der en prosessor kjører flere tråder (lettvekts prosesser) og ved lesing/skriving til lager med lang ventetid, så byttes kontekst og prosessoren jobber med noe annent inntil resultetet fra minne-aksessen er ferdig. Denne teknikker reduserer "overhead'en" ved å ha et distribuert, delt lager betydelig.
I tillegg til å ha delt logisk lager og mulighet for programmenring med prosessorkommunikasjon via dette lageret, støtter Cray T3E både synkronisering i SIMD of MIMD typer av kommunikasjon. T3E har mange biblioteker for meldingsutveksling (MPI/PVM…) og kan også emulere en SIMD maskin på alle eller deler av nodene.
Cray T3E bruker et operativsystem som heter UNICOS/mk som er en skalerbar versjon av deres UNIX operativsystem UNICOS. Cray påstår at UNICOS/mk er verdens første skalerbare operativsystem. UNICOS basert på UNIX system V.
UNICOS/mk er et distribuert operativsystem med en liten mikro-kjerne som kjører på hver node. Denne kjernen er kun et minste minimum av hva som trengs på hver node, og en har et hierarki av OS-servere som støtter hver node, noen lokale servere som tar seg av lokale ting og noen globale som tar seg av globale ting som fil-allokering.
Den store forskjellen fra andre MPP systemer er at systemet er distribuert, ikke replisert. På f.eks. Intel Paragon er hele operativsystemet replisert på hver eneste node. Dette fører til dårlig minneutnyttelse og vanskeligere systemadministrasjon. En systemadministrator kan administrere hele systemet som et "single-system-image".
Operativsystemet bruker 64 bits adressering, noe som gjør det mulig å støtte veldig store datastrukturer og minnestørrelser. UNICOS/mk støtter den distribuerte I/O-arkitekturen på følgende punkter:
En av de virkelig store nyhetene ved Cray T3E er det nye skalerbare I/O-systemet. Det nye er et konsept som Cray kaller GigaRing. En GigaRing er en skalerbar toveis I/O-kanal som gir høy I/O båndbredde og større pålitelighet. Båndbredden på kanalen er 1GByte/s, noe som sikrer rask akseess til I/O-enheter som netverk, pritere, andre Cray maskiner osv. I/O er skalerbart da man har en GigaRing for hver 8. prosessor (luftavkjølt versjon) eller 16. prossessor (veske-avkjølt). Alle I/O-kanaler kan dessuten nåes og kontrolleres fra alle prosessor-elementer. Det betyr at antall I/O kanaler vokser gjevnt med antall prosessorer. Det fører igjen til at man slipper den flaskehals som I/O normalt fort blir på en massiv parallellmaskin (MPP).
Med maksimalt antall prossessorer og I/O kanaler ( 2048 prossesorer og 128 I/O kanaler) får vi en maksimal I/O båndbredde på hele 128 Gbyte pr. sekund. Og da hver I/O kanal kan betjene en disk på inntil 1.6Tbyte, får vi en total diskkapasitet på 204,8 TByte.
På hver I/O node kand man koble på mange forskjellige I/O enheter : Nettverk, disk, tape, alle mulige SCSI enheter (CD-ROM etc.), 32-bit eller 64-bit ANSI HIPPI kanaler (på 100 til 200 Mbytes/s).
Cray T3E er laget med fokus på størst mulig pålitelighet og tilgjengelighet. Feilende komponenter (prosessorer, I/O kanaler, interprosessor kanaler) kan utkobles individuelt. Man har dessuten normalt et ekstra (redundant) prosessor-element for hver 128. node. Hvis en prosessor går i stykker, blir en redundant prosessor automatisk koblet inn. En modul med en ødelagt prosessor kan dessuten skiftes ut uten å måtte slå av eller boote maskinen (såkalt "hot-swap").
Operativsystemet er også meget pålitelig. Det er basert på et system (UNICOS) som er nøye uttestet og vel brukt i10 år. Man har en teknikk som kalles sjekkpunkt/restart som gjør at ved hardware-feil, strømbrudd, naturkatastrofer ol. kan man etter å ha reparert hardware gjenstarte fra siste sjekkpunkt og kjøre videre. Det gjør det mye enklere enn å måtte starte fra da siste backup ble tatt.
 Figur 2-3
: Noder og GigaRinger kan kobles ut og data blir automatisk rutet
rundt det feilende elementet
Figur 2-3
: Noder og GigaRinger kan kobles ut og data blir automatisk rutet
rundt det feilende elementet
Hver Gigaring er koblet til maskinens system torus og I/O systemet vha. flere porter. Hvis en I/O vei skulle falle ut, vil alle data bli rutet rundt dette stedet vha. alternative veier. Det er også mulig å gjøre "hot-swap" av I/O moduler. Figur 2-3 viser hvordan det at en node eller GigaRing faller ut ikke forhindrer I/O strømmen.
I dette kapittelet vil jeg se litt nærmere på en del av det skalerbare I/O systemet i den nye Cray T3E, nemlig deres nye GigaRing. Grunnen til at jeg vil fokusere på dette emnet er at det her er mye nytt i forhold til forgjengeren T3D.
Dette I/O systemet er ikke spesifikt laget for T3E, men kommer til å bli brukt av Cray både i MPP maskinene (T3E, T3F ??) og i vektor-SMP (symmetrisk multi-prosessering) maskinene (neste versjon av T90, J90).
Grunnfilosofien bak dette systemet er å forhindre at I/O blir en flaskehals. Det er tilfellet ved de fleste andre MPP systemer. I/O kapasiteten må vokse i samme takt som antall prosesserings-elementer.
 Figur 3-1 : GigaRinger
Figur 3-1 : GigaRinger
GigaRingen er som nevnt i kapittel 2.6 er par av motgående ringer som kobler sammen to systemnoder. Til disse gigaringene kan man koble til forskjellige I/O enheter som nettverk, disk, tape osv. Hver systemnode sender data på to 32-bits ringer og slår sammen disse slik at den noden som skal bruke GigaRingen når 64-bit data.To systemnoder er koblet sammen med normalt to GigaRinger. Under normale forhold operer disse to ringene som to separate ringer.
Men hvis en av GigaRingene feiler, da benyttes kun den ene ringen og all I/O trafikk på den ødelagte ringen blir sendt på den feilfrie. Dette er vist i den høyre delen av Figur 2-3.
Hvis en systemnode skulle feile, så stopper heller ikke I/O systemet. Da forandres det på hver side av den ødelagte noden slik at alle I/O enheter fortsatt kan nåes.
Systemnodene kommuniserer over GigaRing I/O kanalen med en pakkebasert
protokoll. Noder sender pakker til andre systemnoder eller til
I/O enheter vha. peer-to-peer meldingsoverføring og DMA
(Direct Memory Access) inn og ut fra nodenes minne. Data og kontrollsignaler
sendes på samme måte. Pakker på inntil 256 byte
kan sendes med lite overhead.I GigaRingen er det implementert
en robust arbitreringsalgoritme som sikrer lik tilgang for alle
enheter til ringen og som unngår vranglåser (deadlocks).
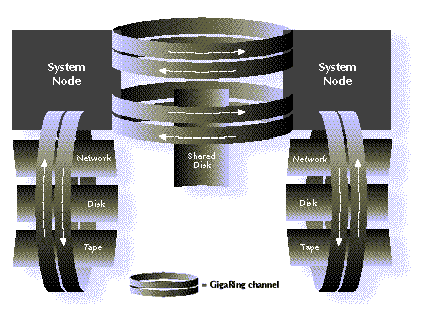
Figur 3-2 :
Oppkoblingen med to systemnoder og en rekke I/O enheter er vist i denne figuren.
Her ser man at to systemnoder er koblet sammen med to GigaRinger.
En fiberoptisk node som man kan koble disk-arrayer eller single disker til. Denne noden kommuniserer med de tilkoblede enheter på 100 Mbyte/s. Det er 5 separate fiberkanaler på hver FCN-1 og hver av disse kan koble sammen totalt 80 stasjoner. FCN-1 støtte RAID 3 og 5.
Denne noden gjør det mulig å bruke gamle Cray Research IPI disker.
Her kan man koble til stanard tapestasjoner med IBM tape interface. Hver BMN-1 har to tape-interface'er.
Disse noden gjør det mulig å koble seg til ANSI standard 32-bits og 64-bits kanaler.(100 eller 200 Mbyte/s). Dette er toveis kanaler, og HPN-2 (64-bit) kan konfigureres til å være 2 stk. HPN-1 (32-bit).
Dette er en node med to Sbusser. Til disse kan man koble til: Ethernet 10baseT kort (ETN-10) og ATM kort (ATM-10).
Denne noden gir en mulighet til å koble til SCSI-2 Fast&Wide Differntial enheter.