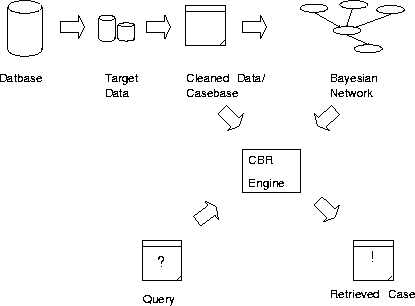
To demonstrate an integrated system, we propose the following algorithm which we will denote CBRDM: A new case description is taken from the user. The CBR engine does a search in the casebase for similar cases. The similarity metric uses a Bayesian network computed from the database for inference such that: If no complete match is found, the most similar case is assumed to be the case which for the features that are different, has the highest probability of having the feature values, given other values and a probability distribution. The procedure of constructing the Bayesian network and Casebase, and an overview of the system is given in Fig 4.4. We will use a database from NOEMIE, OREDA, which is described in chapter 5. Then we use Bayesian Knowledge Discoverer to construct the Bayesian network. The whole process of constructing the casebase and network is explained in the next chapter. We use the Case-Based Reasoning tool KATE to compare with the results obtained from the new Systems. Both KATE and Bayesian Knowledge Discoverer are briefly explained in section 4.5.
To better explain the use of the Bayesian network, we illustrate the new method for computing similarity metrics by an example:
The following case is given by the user:
ACCIDENT = ? SURFACE = OILY GLOVES = NO POSITION = BOWINGThe following cases exist in the casebase:
HAND-CRUSHED OILY NO UPRISED HAND-CRUSHED NA NO BOWING FOOT-CRUSHED OILY NO BOWING HAND-CRUSHED OILY NO BOWING
If we then can derive the following probability distribution from a network using Bayesian inference:
P(HAND-CRUSHED|UPRISED,NO)=0.000001 P(HAND-CRUSHED|BOWING,NO)=0.000100 P(FOOT-CRUSHED|BOWING,NO)=0.000001
Then, hand-crushed would be the most similar, because it has the highest probability, given the other feature values.
The algorithm for the system is shown in pseudo-code in Fig 4.4.
We use the following similarity metric:
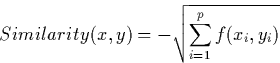
Where x and y are two cases, p the number of features and f is defined as:
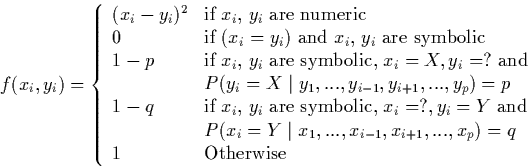
Where the probabilities are inferred from the Bayesian network.
The strengths of this approach are that the similarity metric is learned from the database, thus it is dynamic and can be updated as new data arrive. It is also easy to control the network for an expert by viewing it in an editor. The tools used in the implementation are described in the next section.
We originally planned to implement algorithms for reuse , revise and retain as well which would make use of the Bayesian network as background knowledge. It was also planned to use Dynamic Link Library (DLL) routines from the tools KATE and Microsoft Belief Networks described in the next section, to reduce implementation time. But this was abandoned due to lack of time and compiler and platform difficulties with the programs available. The program was therefore created with Borland C++ version 3.1 for DOS, and routines for case management and Bayesian inference was implemented. The source code can be found in appendix E.