



Next: Decomposition of CBR
Up: Case-Based Reasoning
Previous: Case-Based Reasoning
CBR can be divided into different methods. Aamodt and Plaza
[4] describe five different methods, which can be
discriminated by their dependency on a large number of cases, domain
knowledge and whether they are able to modify solutions to suit new
problems.
- Exemplar-based reasoning - CBR is seen as a task of classifying
a new case into a given set of classes which consists of previously
experienced (prototypical) cases. The classes represent the set of possible
solutions, and it is therefore not possible to modify a solution. This
method is useful for weak theory domains.
- Instance-based reasoning - A highly syntactic specialization of
Exemplar-based reasoning without domain knowledge.
- Memory-based reasoning - The collection of cases is seen as a large
memory, and reasoning consists of accessing and searching the memory.
- Case-based reasoning - Typical CBR systems have some richness of
information, and a certain complexity in its internal organization. It is
able to modify, or adapt a retrieved solution when it is used to solve a
problem with another context than described in the case.
- Analogy-based reasoning - Methods that are able to solve problems
by using experience from a different domain.
The first three methods typically require more recorded cases than the
latter two, because they lack domain knowledge.
Figure 2.1:
A Knowledge Rich CBR System.
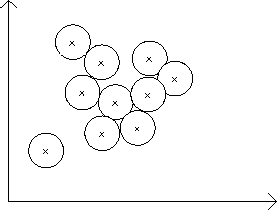 |
A CBR-method which relies heavily on domain knowledge is called
knowledge rich . This is illustrated in Fig 2.1, where
the crosses indicate cases, and the circle the area of new cases that
the system is able to handle with the domain knowledge and the case. By
a case in these systems, we mean ``a user experience''.
Figure 2.2:
A Knowledge Poor CBR System.
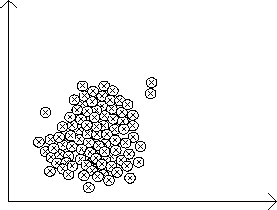 |
If the system relies heavily on cases, it is called knowledge poor .
This is illustrated in Fig 2.1. By cases we here use a more modest
definition, ``a data record''. Some existing systems are placed
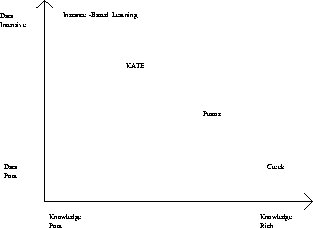
according to their dependency on data and knowledge in Fig 2.1.
The systems that will be further discussed here are KATE and Creek.
Figure 2.3:
Dependency on Knowledge and Data for Some Existing Systems.
 |
Next: Decomposition of CBR
Up: Case-Based Reasoning
Previous: Case-Based Reasoning
Torgeir Dingsoyr
2/26/1998